Popular blog about our research and activities
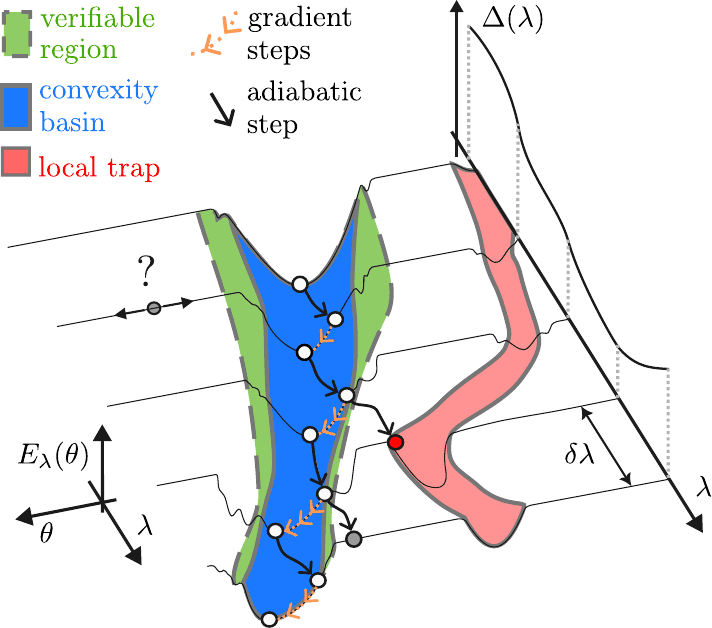
A VQE that warms up — and checks its own work
Random-start VQE is famous for getting stuck on flat loss landscapes or in the wrong valley. Our recent paper sidesteps both with a simple trick — ease into the hard problem along an adiabatic path — and adds a way for the algorithm to certify its own answer at runtime.
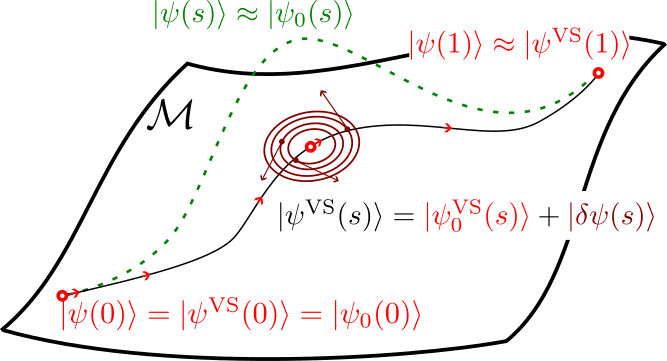
Exploring the Variational Ground-State Quantum Adiabatic Theorem: Implications for Quantum Computing
In this post, I’ll explore the variational ground-state quantum adiabatic theorem and its exciting potential for developing new algorithms tailored for NISQ (Noisy Intermediate-Scale Quantum) devices. By leveraging this theorem, we can enhance the performance of quantum algorithms while navigating the limitations of near-term quantum hardware.
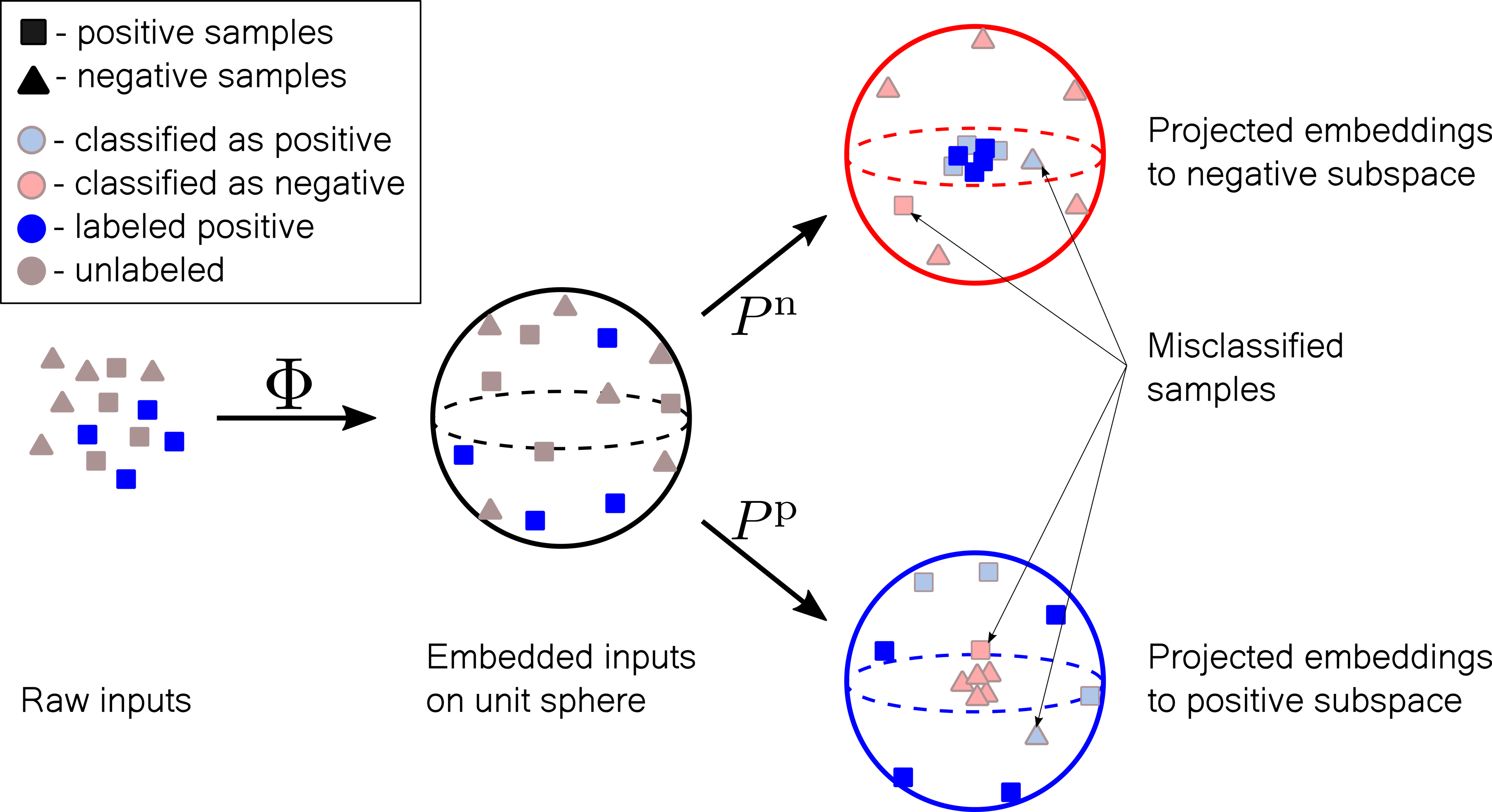
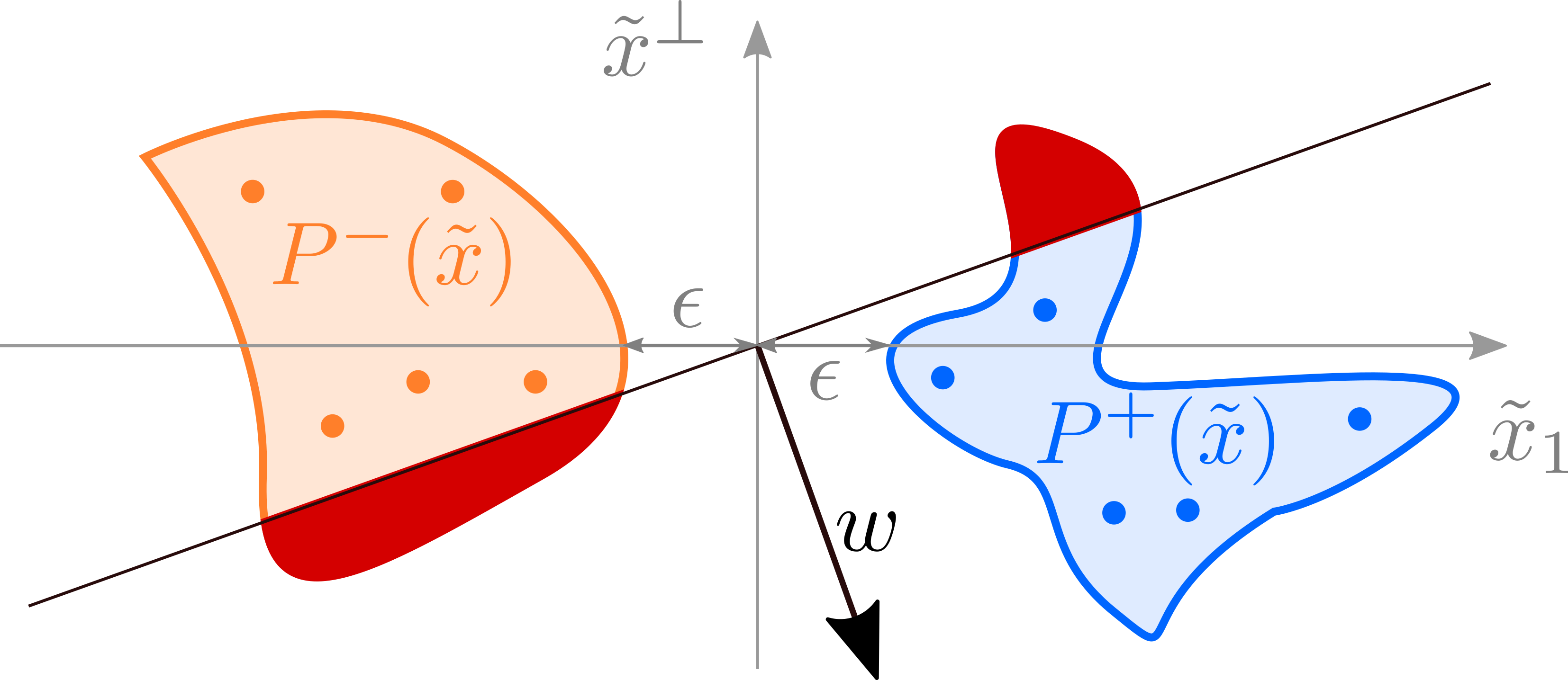
Positive unlabeled learning with tensor networks
In this post I describe a tensor network approach to the positive unlabeled learning problem, which achives the state-of-the-art results on the MNIST dataset and categorical datasets.
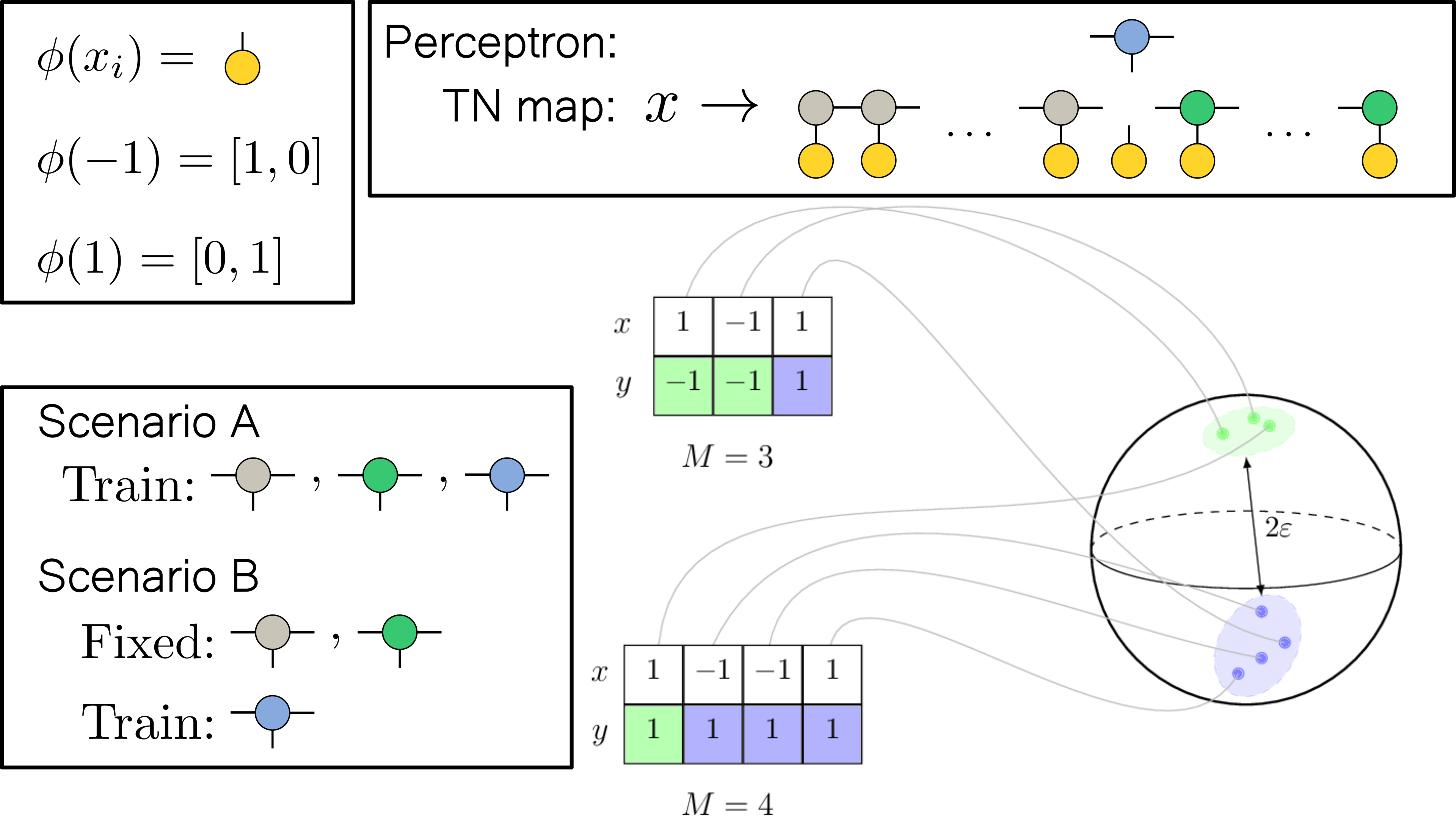
Phase transitions in local rule learning
I will discuss the connection between the perceptron grokking scenario and the problem of learning local rules.
Perceptron grokking
A sudden transition to zero test/generalization error in the terminal training phase in learning algorithmic tasks with deep neural networks (named grokking) has recently attracted a lot of attention. Here we discuss a simple perceptron grokking model with exact analytic solutions.
Application of deep tensor networks to MNIST and permuted MNIST
In this post I present results on applying deep tensor networks to the MNIST and permuted MNIST classification tasks.

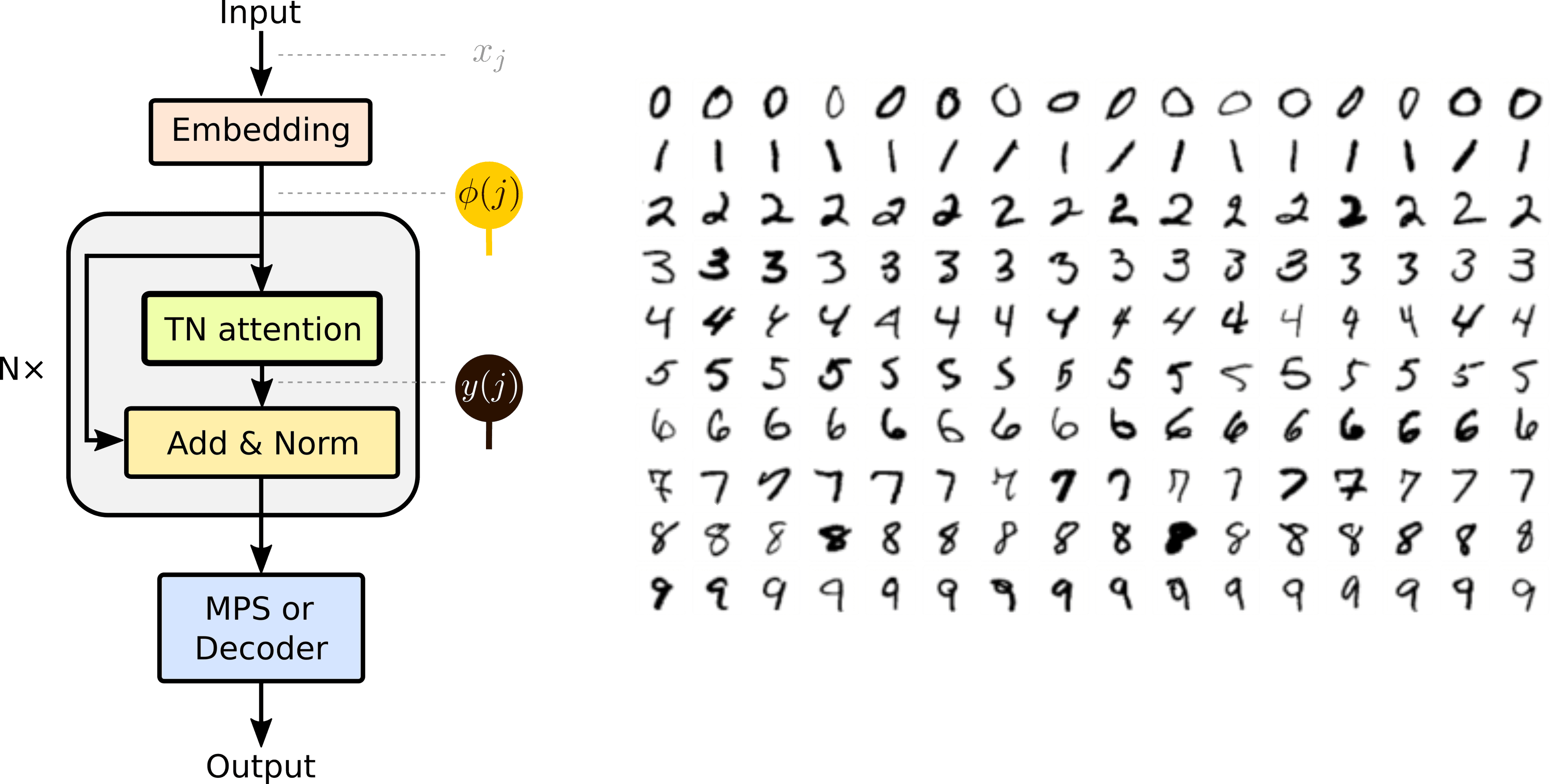
Deep tensor networks with the tensor-network attention layer
Tensor networks in machine learning are typically applied as linear models in an exponentially large Hilbert space. In this post, I describe a tensor-network attention layer, which enables us to build deep non-linear tensor-network models.
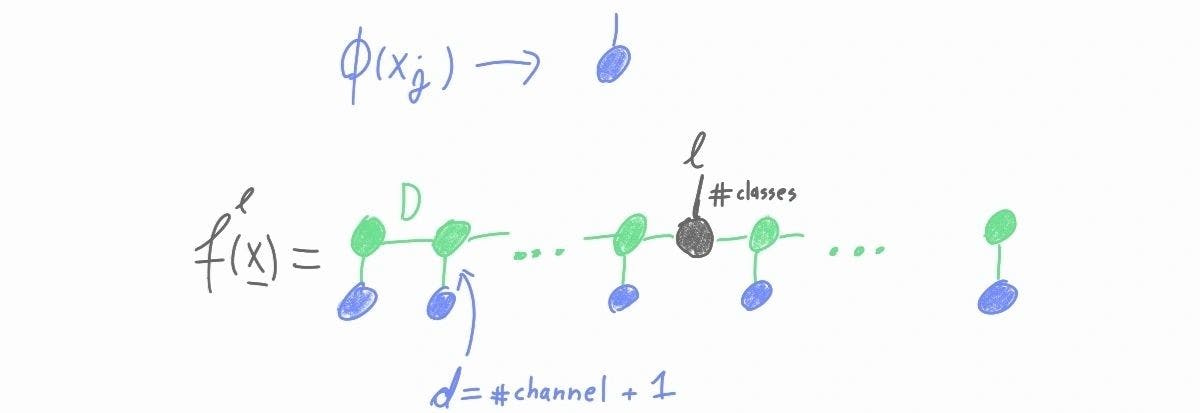
Improved MPS classifier baselines on simple image datasets
In ML research, the baseline models are often not given enough attention when improving existing approaches or implementing new ones. Here we will discuss improving the vanilla matrix product state classifier on simple image datasets by enhancing the data augmentation and the training procedure.
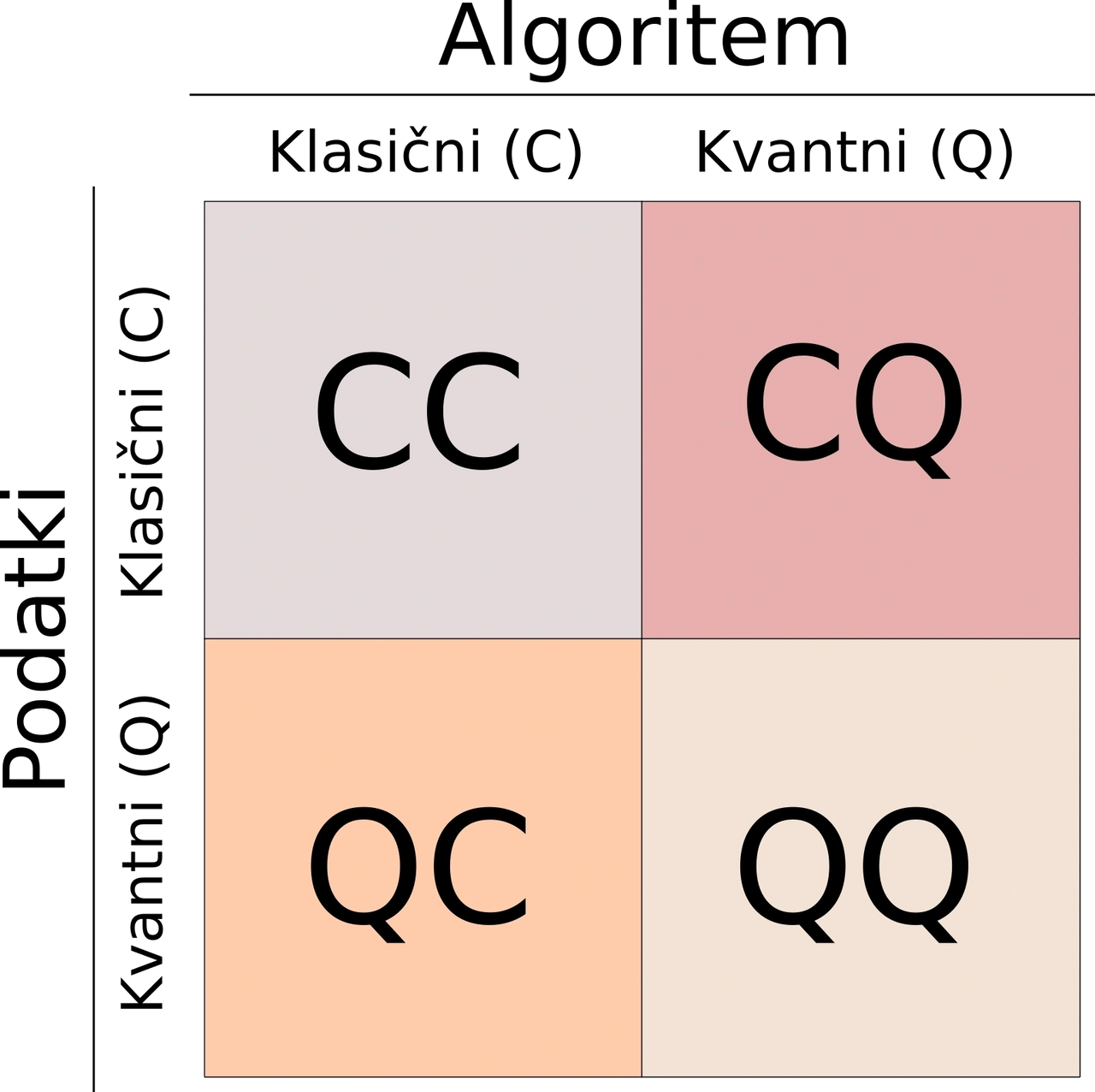
Popular article in Presek: A short overview of quantum machine learning
A popular science article published in Presek (2021, issue 3, category computer and information science) presenting a short overview of quantum machine learning. A translation of the article can be found below.